
Scriptura Obscura
(Or, how I stopped waiting for OpenAI’s multi-modal API’s and found BLIP-2)

It isn’t currently possible to use one of the most intriguing features of GPT-4. When OpenAI announced GPT-4 as a multi-modal (images + text) large-language model, they showed several examples using an image as an input to a question. For instance:

Two-months post-launch, it still isn’t possible to use images as input either as part of ChatGPT Plus or any of the public OpenAI API’s. It’s curious that something this powerful is being held back. Does it not consistently work as well as these examples show? Is it too easy to abuse? Too slow or expensive to run? Or does OpenAI have so much on their plate that they decided to deprioritize this in favor of other features? It doesn’t seem like anyone outside of OpenAI knows (but if you do, I’d love to hear from you).
Image recognition and multi-modal models are not unique to OpenAI, so after seeing these examples, I was excited to see what else was out there.
AWS Rekognition
One of the easiest places to start is a service that AWS provides called Rekognition. Rekognition isn’t an LLM, but does claim to “automatically label objects, concepts, scenes, and actions in your images, and provides a confidence score.”
Here’s what Rekognition says about the same image.
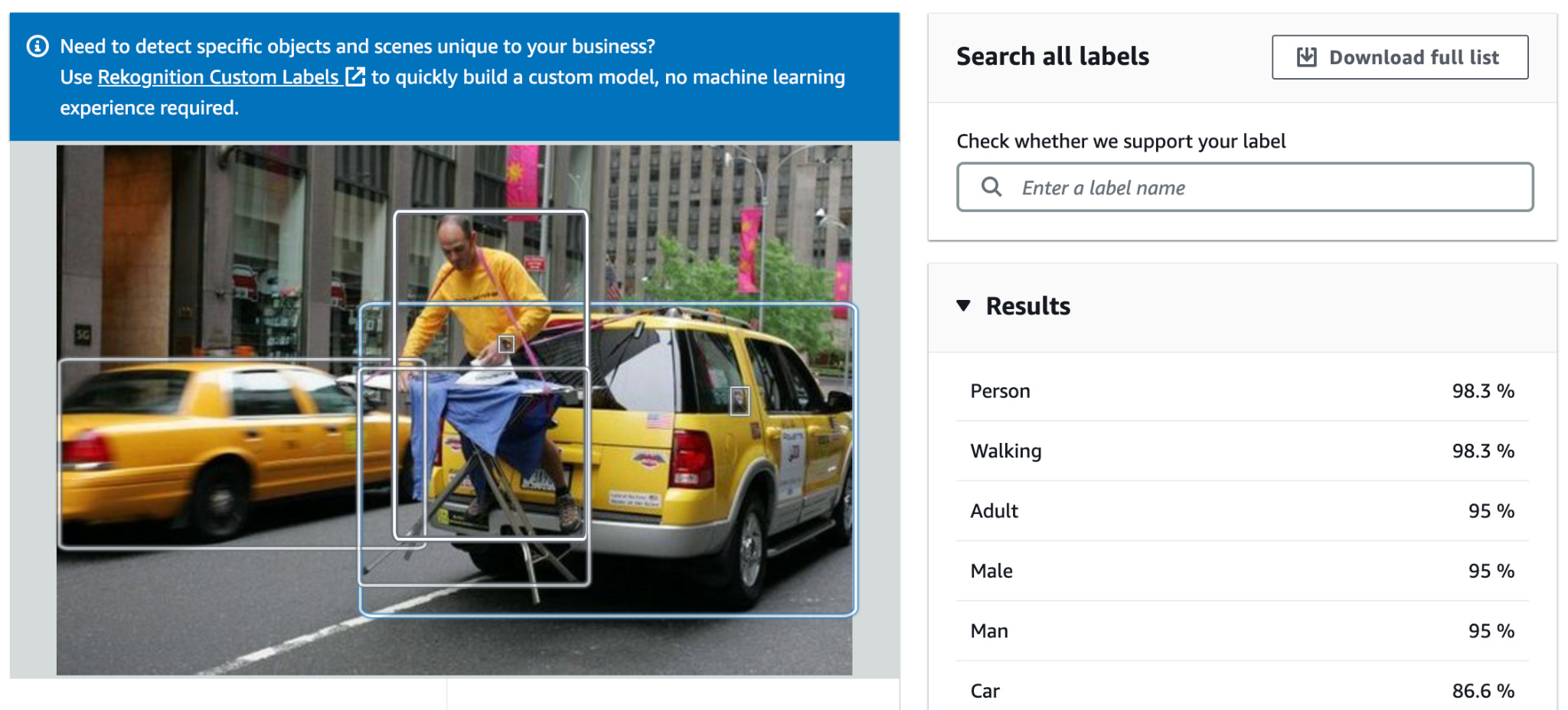
It’s 98.3% confident that there is a “person” in the image, which is correct. However, it’s equally confident that the person is “walking,” which is wrong. This is a model that has been trained to recognize a very specific set of objects, and the results read that way. It’s looking for objects it knows about, but it isn’t able to tell you what the overall image is actually about.
Admittedly, this is an odd image, so what if we give it a more traditional image? Here’s one that might be found in a personal photo album.
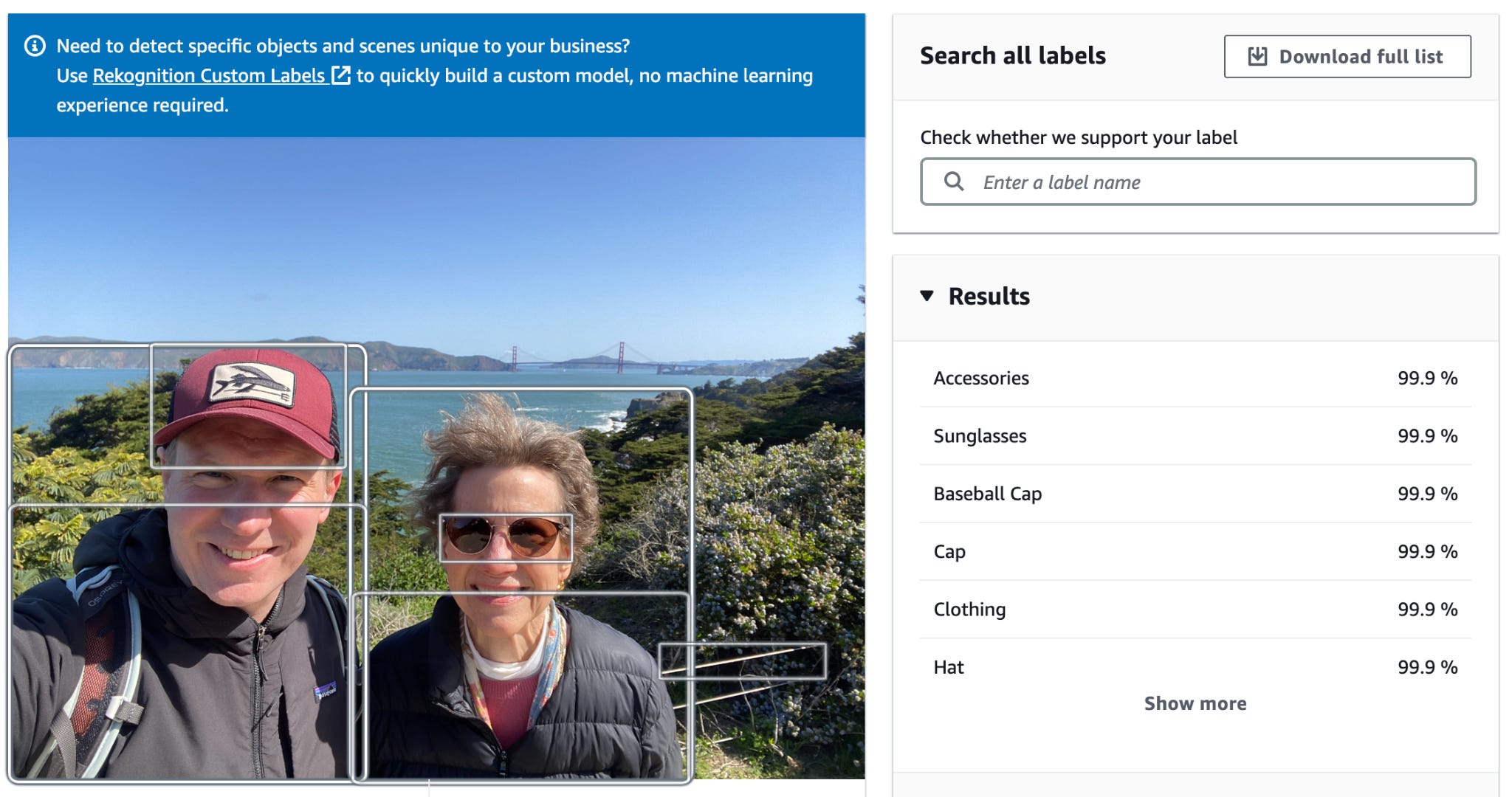
It finds a lot in this image that it is very confident about. There are 11 tags with 99.9% confidence and 29 tags with at least 95% confidence. Some are outright wrong, like “weapon,” which it finds with 82.8% confidence. In contrast, “bridge,” which is one of the most visually identifiable aspects of this image to a human, is way down the list with 56.9% confidence. It also never identifies which bridge this is, in spite of it being a well-known landmark.
Even with a “real-world” image, the results feel very mechanical. It’s slicing the image up into lots of little pieces it recognizes, sometimes incorrectly, but never really tells us what the image is about the way the GPT-4 examples appear to.
I wasn’t expecting Rekognition to be as good as GPT-4, but my experience with it felt too mechanical to be useful for helping me better search my personal images. I wanted to see what else was out there.
BLIP-2
Enter BLIP-2. BLIP-2 was announced 3 days after GPT-4 and comes out of Salesforce Research. It is a multi-modal model that works on top of existing pre-trained LLM’s and image encoders. As a result, it is much more efficient than training a multi-modal model from scratch. In contrast to GPT-4, it’s also open source.
I was excited to see how BLIP-2 performs, so I built a simple app that sends an image to an instance of BLIP-2 running on my laptop(!) and about a second later an automatically generated caption appears below the image. Here’s the strange taxi image that OpenAI used:

The response is not as detailed as GPT-4 but is worlds apart from Rekognition. This doesn’t feel mechanical – it’s a description a human could have given the image. I’m also not prompting BLIP-2 with a question the way the GPT-4 example is structured, so we wouldn’t necessarily expect it to respond in the same way (more on this in a future newsletter).
The performance of BLIP-2 is impressive. Before this, I had no idea that it was possible to run a LLM of this class on a laptop and perform an image inference in about a second. This makes it suitable for many real-world applications. As a point of reference, the image inference examples shown in the GPT-4 livestream took about 40 seconds to return and were almost certainly running on hardware significantly faster than my MacBook Pro.
Here’s how BLIP-2 does with the family photo image.

Wow! This is impressive. No location or camera metadata was used to generate this caption, and not only did it identify a bridge, but it named the specific bridge correctly. Also, there isn’t a lot of noise in the description – nothing about a “baseball cap” or “accessories” – it’s to the point and much closer to how a human would describe the image.
Though this example is impressive, BLIP-2 doesn’t always provide results that are this strong. Here’s a similar photo that produces a much less specific caption.

When BLIP-2 doesn’t produce a great result, it’s often because it isn’t specific enough. Though this caption is correct, it feels generic.
Overall, BLIP-2 is a remarkable mix of efficiency and quality of output. It produces results that are good enough – and generally better than other approaches I’ve tried – fast enough that they can be used in real world applications today.
Let’s look at some other examples that give a flavor of the capabilities of BLIP-2.

It’s very useful that you don’t have to train it on specific objects. I wouldn’t think of putting “sprinkles” into the label database, and yet, that detail provides a more accurate description of this image.

Seeing a caption like this makes me want to generate captions for all my personal photos, if for no other reason than to make them more searchable. The cost (a couple of days of processing) feels well worth the benefit, and a significant step beyond what current photo management solutions offer.

It’s powerful that it works on any image, even old photos that have no metadata.

It isn’t perfect (technically there are three giraffes), but it’s getting the gist. It’s worth knowing that when it generates a caption, it downsizes the image significantly to improve performance. You could imagine that the baby giraffe is hard to see in a thumbnail image and may be one of the reasons it isn’t counted in the caption.

A geotag for this photo might also identify the Golden Pavilion, but many photos don’t have geotags. And a geotag doesn’t know about the image content. Is it actually a photo of the Golden Pavilion, or is it a photo I took of something else while I was there? In general, I find the output of BLIP-2 to be very complementary to other ways photos can be automatically indexed – timestamps, geotags, face recognition, and OCR. There are also ways in which these different streams of metadata can reinforce each other (more on this in a future newsletter).

BLIP-2 feels remarkably resilient. A child painting a truck isn’t a common activity, and yet it gets the key details right in a way that sounds much more human than an explosion of tags with confidence scores. (Admittedly, this caption would sound even more human if “with paint” was left off.) This shows the power of building on top of an LLM vs. a system that only recognizes specific objects.
Scriptura Obscura
From the earliest days of the camera obscura in the 16th century, cameras have involved a black box and a bit of magic to produce an image. With GPT-4 and BLIP-2, we see the beginnings of a new kind of camera that still uses a black box and a bit of magic, but produces words rather than images. Having explored image recognition technology on and off for over 20 years, I find this development to be among the most significant I’ve ever seen.
BLIP-2 is an impressive piece of technology that I’m excited to continue exploring. In our next adventure, we’re going to use BLIP-2 to look deeper and see what else we can find in an image beyond a simple caption.
Thank you for reading, and please consider subscribing if you’d like to join me on our next adventure in AI at Home.
This is great. I'm curious about the criteria of 'a description a human could have given the image'. It begs the questions for me, 'Where does description end and storytelling begin?' I wonder about these tools being able to imagine (what a word!) a story from an image.
I'm curious about how these AI tools treat different genres of written expression. For example, what would you get if you ask for a "caption," a "description," an "encyclopedia entry" or a "critical review"? Or, to play the Cindy Sherman card, you asked instead for that particular kind of caption she referenced in her "movie still" work. Going a little farther afield, how would it handle a request for an "oral response" to a photo from a child, adult or professional photographer? To my mind, these questions all get at what AI can do in framing searches and constructions for known and unknown audiences. And if it could do well enough at that, specifying the audiences--for a given caption or comment or description, as well as for a particular visual image or material--might be one of it's more powerful applications.